Carleton University - School of Computer Science Honours Project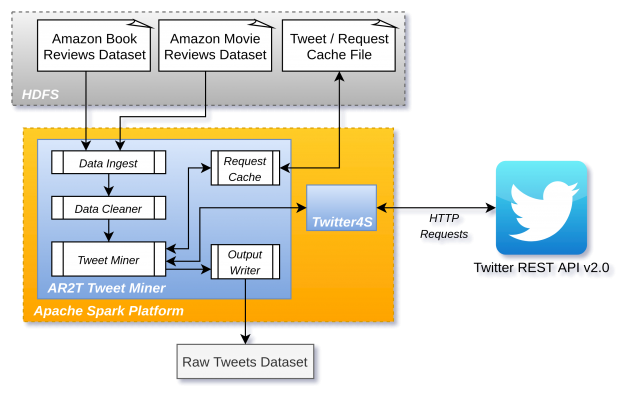
Winter 2021
Extending Heterogeneous Recommenders Beyond First-Party Datasets
ABSTRACT
In today's day in age, recommender systems are ubiquitous among e-commerce players, advertising agencies, and social media platforms. The main premise of a recommender system is relatively simple: based on a temporally learned dataset, make effective guesses and predictions to find entities relevant to the user. Therefore, the data being leveraged to make these guesses is integral to the success of the system's accuracy. Many companies purchase datasets derived by online advertising firms; however, can these preference datasets be mined through third parties, such as Twitter?
Furthermore, there has been significant developments in the area of heterogeneous recommender systems. Many platforms focus on homogeneous data as their platform does not span multiple domains of data; however, for the vast majority of platforms there is a strong heterogeneity in the domains that are spanned (i.e, Amazon).
This paper explores data mining for heterogeneous recommender systems, namely mining relevant data from Twitter, along with the interaction with the third party datasets with first party datasets.