Carleton University - School of Computer Science Honours Project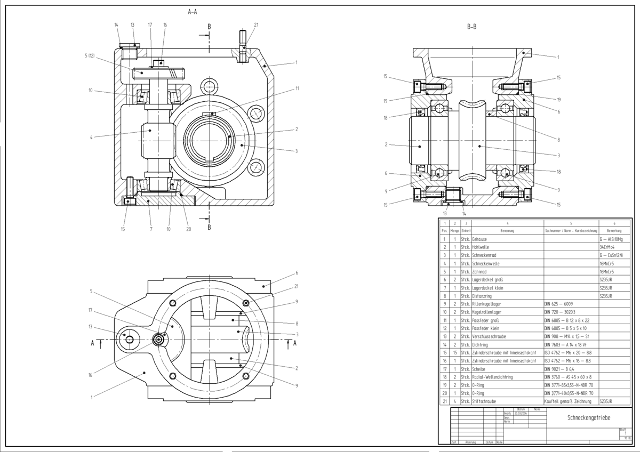
Fall 2017
Extracting Mechanical Structure from Industrial Designs
ABSTRACT
Natural Language Processing is applied to a practical problem facing the manufacturing industry, where industrial design files are not conducive to managing materials and components in a machine-readable format. Free text from diverse design files is analyzed, and the structure of the design is inferred based on known examples of text. Principal observations are:
1. Given robust training data, Bayesian classification of part numbers by three-character trigram performs well.
2. Part numbers cluster poorly when grouped by Levenshtein Distance or Longest Common Subsequence.
3. Technical shorthand and abbreviations follow a grammar which is machine-readable.
4. A standard English Corpus, such as the Brown Corpus, when augmented by a technical dictionary and training data, can be used to parse this grammar.
5. Abbreviations, mixed-character alphanumeric strings, and non-standard English terms combine to form quasi-word collocations, which can be identified by statistical analysis in the same way as English word collocations.
6. The type of material or item, if any, described by a collocation discovered in this way, can be learned by a machine, given robust training data.
7. The parent-child relationship between types of materials can be learned through statistical analysis.