Carleton University - School of Computer Science Honours Project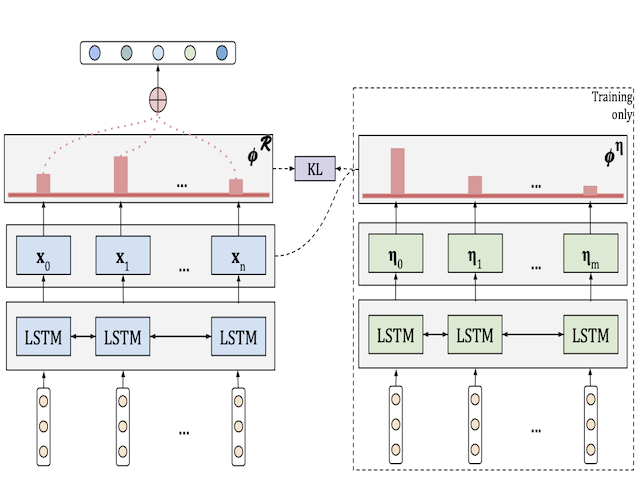
Winter 2020
Do Human-Written Explanations Make Neural Attention More Interpretable?
ABSTRACT
Toxicity on social media has become increasingly prevalent in political discourse as polarity and tension continues to rise. As the volume of problematic content increases, it quickly becomes impossible to manually review. This has led to the application of technological approaches, such as deep learning, to flagging toxic content. However, such approaches are difficult to interpret, and are susceptible to latent bias and adversarial attacks.
We propose a novel method for text classification with improved local post-hoc interpretability without compromising performance by learning from human-written rationales. We leverage the rationales during training by identifying semantic overlap with hateful comments, which we use to derive word importance scores using the neural attention mechanism. Our method is able to learn from rationales without requiring them for prediction at evaluation time.